
The Enterprise Cloning Challenge
Picture this scenario. Your team needs to replicate 500 Jira issues across three projects by next week. How would you do this?
At enterprise scale, bulk cloning isn’t just admin work, it’s mission-critical infrastructure management. Manual approaches that work for small teams become operational risks when you’re dealing with complex project hierarchies and tight deadlines.
Here’s why: enterprise-scale bulk cloning isn’t just about moving data from Point A to Point B. You’re dealing with interconnected webs of epic hierarchies, custom field mappings, and issue dependencies that took months to build. Data integrity, hierarchy preservation, and workflow continuity are all at risk when cloning processes break down.
The stakes? Teams miss sprint deadlines and projects derail. And somewhere, a project manager is explaining to executives why the “simple copying task” turned into a three-week recovery operation.
Business Drivers Behind Enterprise Bulk Cloning
Why do organizations even attempt bulk issue cloning at scale in the first place? The business case is compelling:
- Time efficiency at scale: You’re replicating thousands of issues with minimal clicks instead of drowning your teams in weeks of tedious manual recreation across global projects. This is critical for enterprises managing hundreds of concurrent projects across global teams.
- Cross-departmental consistency: Multi-project organizations need uniformity because standardized processes ensure compliance and prevent costly workflow variations that undermine governance structures.
- Large-scale testing and QA: Complex test cases and scenarios need quick reproduction across multiple environments. This is essential for enterprises that have rigorous quality assurance requirements and regulatory compliance breathing down their necks.
- Project migration and consolidation: When M&As happen, organizational restructuring becomes inevitable. During these chaotic periods, you need to move massive volumes of issues seamlessly while maintaining data integrity and audit trails.
- Enterprise process standardization: Proven Jira templates and workflows should duplicate across departments and regions effortlessly, ensuring HR onboarding sequences, service management templates, and compliance processes stay consistent company-wide.
- Cross-team synchronization: Align related teams with identical issue structures so global departments operate from the same playbook, reducing miscommunication and improving scalability.
- Enterprise risk reduction: Automated cloning eliminates manual entry errors and preserves data quality at scale. This is important for organizations where data integrity impacts compliance, reporting, and strategic decision-making.
Why Native Jira Falls Short for Enterprise Needs & Its Impact
Jira’s native cloning feels adequate until you hit enterprise scale. Here are the critical limitations and risks most teams don’t anticipate:
Risk Category | Native Jira Limitation | Enterprise Impact |
Manual Operations | Limited bulk cloning functionality available – restricted to same-project operations with quantity limits per batch. | Teams waste weeks manually copying hundreds of issues one by one. |
Broken Hierarchies | Epic-child relationships are preserved, but relationships among child issues may be lost. Native Jira also limits hierarchy cloning to two levels, whilst third-party apps can handle deeper hierarchies. | Sprint planning becomes impossible when child issues lose relationships between each other. |
Custom Field Loss | Limited customization (e.g., renaming issues) prevents field remapping and transformation rules. | Reporting dashboards break, and automated workflows stop functioning. |
Missing Context | Attachments and historical data are often skipped during operations. | Critical project documentation and decision history vanish forever. |
Performance Limits | Memory-intensive operations can cause system timeouts in Jira Server/Data Center environments. Jira Cloud performance remains stable due to limited bulk operations. | Large enterprise projects fail halfway through, leaving corrupted data structures. |
The enterprise reality is harsh but simple: native tools were designed for small-scale operations, not complex organizational workflows across multiple teams and projects. Jira’s native capabilities become a bottleneck, not a solution.
Epic Clone: Built for Enterprise Scale
Fortunately, where native Jira stumbles, specialized tools step up. We designed Epic Clone app specifically to handle the complexities that break standard cloning workflows at enterprise scale.
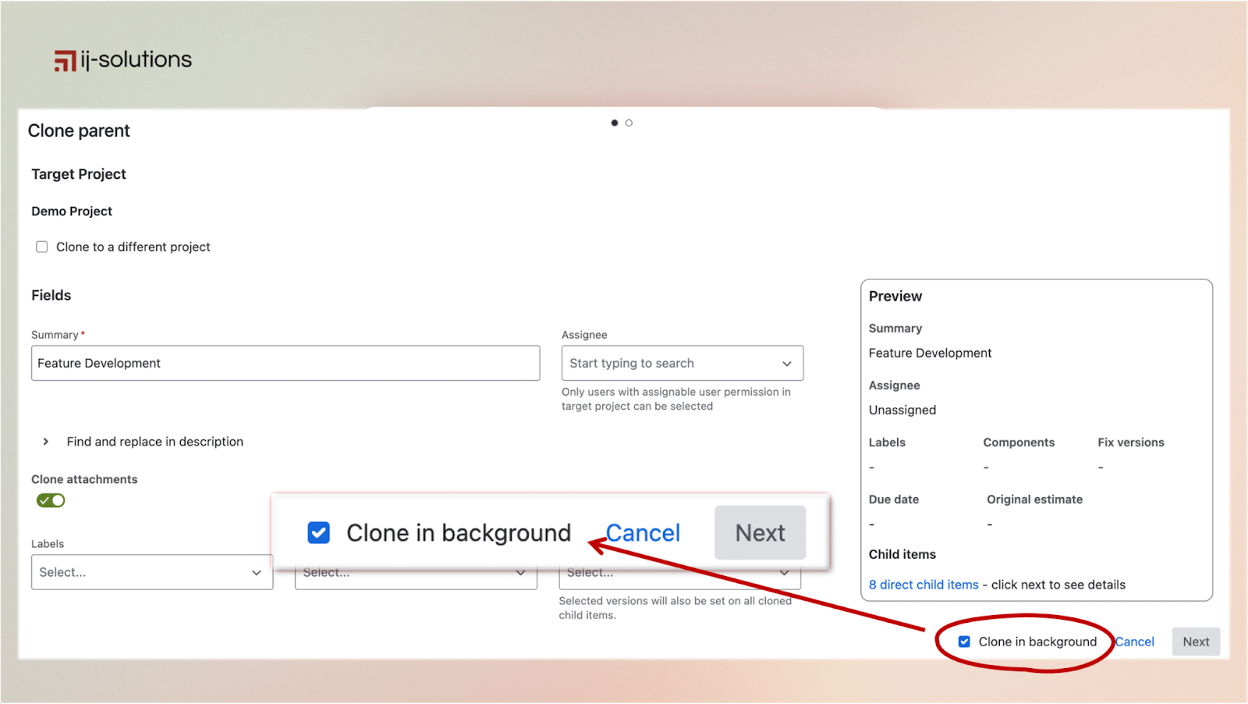
- Background processing: Handles 15-minute runtime for massive projects without blocking dialogs or freezing your interface, letting teams continue working while complex cloning operations run seamlessly behind the scenes.
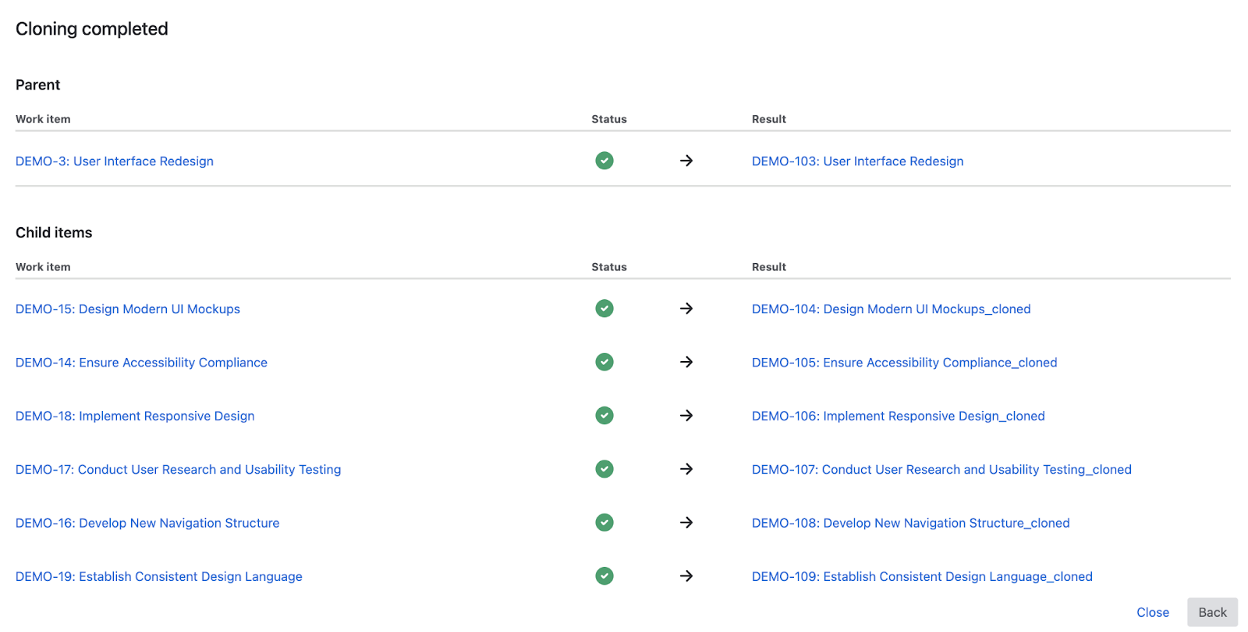
- Hierarchy preservation: Complete epic → story → subtask chains are maintained automatically with all parent-child relationships intact, eliminating the manual reconstruction work that destroys productivity in native Jira.

- Attachment handling: You can enable or disable attachment cloning per project, meaning you transfer only absolutely important files while avoiding system bloat from unnecessarily large documents that slow down operations.
- Cloning REST API: Automate bulk cloning operations through REST API, enabling scheduled cloning jobs and integration with external systems for streamlined workflow automation across your entire organization.
- Progress transparency: Source and target summaries confirm successful cloning operations for all users. Additionally, administrators gain valuable insights through usage statistics that track how frequently the app is used and the total number of issues cloned across the instance, providing data for monitoring adoption and system utilization.
What takes hours of manual work happens in minutes with automated processing, transforming bulk cloning from a dreaded administrative burden into a strategic operational advantage.
Strategic Recommendations for Safe Bulk Cloning
Enterprise bulk cloning isn’t just about moving data faster. It’s about maintaining the complex relationships and hierarchies that make Jira valuable while scaling operations without breaking workflows.
To get it right, follow these strategic recommendations:
- Define exactly what needs cloning and why. Are you replicating a single product rollout or duplicating a multi-region launch? The distinction matters because scope creep exponentially increases complexity and failure points.
- Validate configurations on limited datasets before scaling. Why? Corrupted hierarchies at enterprise scale create cascading failures that require weeks to untangle. Preventing rework saves time and preserves team credibility.
- Leverage apps like Epic Clone that preserve hierarchies automatically. Native Jira cloning can break issue links. Epic Clone maintains parent-child relationships and custom field mappings that took months to establish.
- Verify cloned data integrity before execution. Spot-checking isn’t enough. Run comprehensive validation on epic hierarchies and dependencies because discovering broken relationships after teams start working derails projects and progress.
Want to scale your cloning operations without the chaos? Try Epic Clone free today and experience enterprise-grade bulk cloning that works.